操作系统常见概念理解
Created by 大红苹果甜原作:Guide哥,来源:JavaGuide(JavaGuide)
操作系统基础
什么是操作系统?
操作系统(Operating System,简称OS)是管理计算机硬件与软件资源的程序,是计算机系统的内核与基石;
操作系统本质上是运行在计算机上的软件程序 ;
操作系统为用户提供一个与系统交互的操作界面 ;
操作系统分内核与外壳(我们可以把外壳理解成围绕着内核的应用程序,而内核可以理解为能直接操作硬件的程序)。
内核:
内核负责管理系统的进程、内存、设备驱动程序、文件和网络系统等等,决定着系统的性能和稳定性。是连接应用程序和硬件的桥梁。内核就是操作系统背后黑盒的核心。
什么是系统调用呢
- 用户态(user mode) : 用户态运行的进程或可以直接读取用户程序的数据。
- 系统态(kernel mode):可以简单的理解系统态运行的进程或程序几乎可以访问计算机的任何资源,不受限制。
我们运行的程序基本都是运行在用户态,如果我们调用操作系统提供的系统态级别的子功能咋办呢?那就需要系统调用了!
也就是说在我们运行的用户程序中,凡是与系统态级别的资源有关的操作(如文件管理、进程控制、内存管理等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
- 设备管理。完成设备的请求或释放,以及设备启动等功能。
- 文件管理。完成文件的读、写、创建及删除等功能。
- 进程控制。完成进程的创建、撤销、阻塞及唤醒等功能。
- 进程通信。完成进程之间的消息传递或信号传递等功能。
- 内存管理。完成内存的分配、回收以及获取作业占用内存区大小及地址等功能。
进程和线程
进程和线程的区别
下图是 Java 内存区域,我们从 JVM 的角度来说一下线程和进程之间的关系
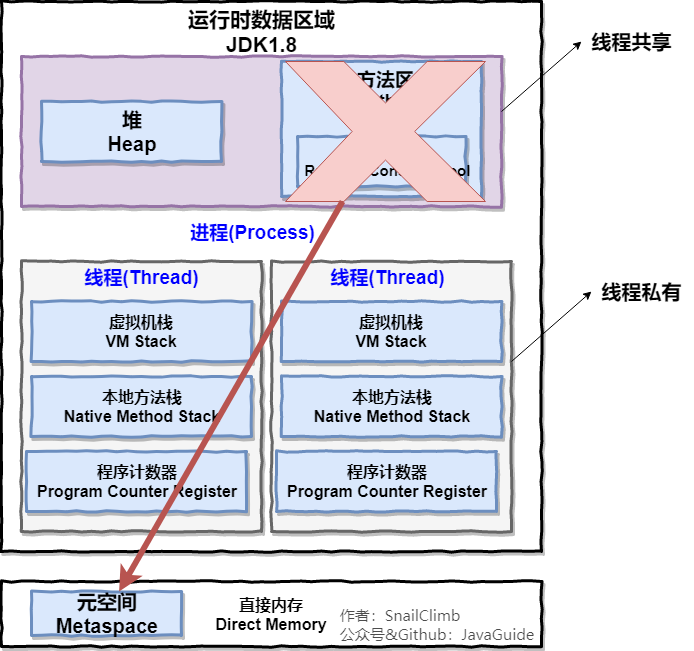
一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)资源,但是每个线程有自己的程序计数器、虚拟机栈 和 本地方法栈。
线程是进程划分成的更小的运行单位,一个进程在其执行的过程中可以产生多个线程。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。
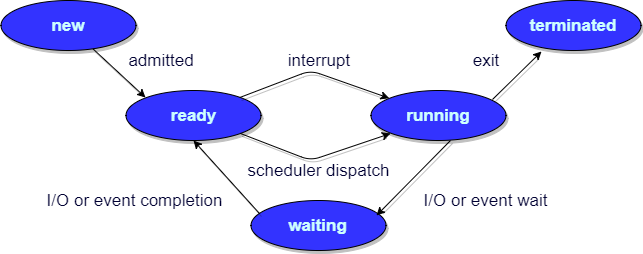
进程有哪几种状态?
- 创建状态(new) :进程正在被创建,尚未到就绪状态。
- 就绪状态(ready) :进程已处于准备运行状态,即进程获得了除了处理器之外的一切所需资源,一旦得到处理器资源(处理器分配的时间片)即可运行。
- 运行状态(running) :进程正在处理器上上运行(单核CPU下任意时刻只有一个进程处于运行状态)。
- 阻塞状态(waiting) :又称为等待状态,进程正在等待某一事件而暂停运行如等待某资源为可用或等待 IO 操作完成。即使处理器空闲,该进程也不能运行。
- 结束状态(terminated) :进程正在从系统中消失。可能是进程正常结束或其他原因中断退出运行。
进程间的通信常见的的有哪几种方式呢?
线程间的同步的方式有哪些呢
线程同步是两个或多个共享关键资源的线程的并发执行。应该同步线程以避免关键的资源使用冲突。
操作系统一般有下面三种线程同步的方式:
进程的调度算法有哪些
先到先服务(FCFS)调度算法
从就绪队列中选择一个最先进入该队列的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用CPU时再重新调度。
短作业优先(SJF)的调度算法
就绪队列中选出一个估计运行时间最短的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用CPU时再重新调度。
时间片轮转调度算法
时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法,又称RR(Round robin)调度。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。
多级反馈队列调度算法
前面介绍的几种进程调度的算法都有一定的局限性。如短进程优先的调度算法,仅照顾了短进程而忽略了长进程 。多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。,因而它是目前被公认的一种较好的进程调度算法,UNIX操作系统采取的便是这种调度算法。
优先级调度
为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推。具有相同优先级的进程以FCFS方式执行。可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
操作系统内存管理基础
操作系统的内存管理主要是做什么
操作系统的内存管理机制有哪几种
连续分配管理方式是指为一个用户程序分配一个连续的内存空间,常见的如块式管理 。
同样地,非连续分配管理方式允许一个程序使用的内存分布在离散或者说不相邻的内存中,常见的如页式管理 和段式管理。
远古时代的计算机操系统的内存管理方式。将内存分为几个固定大小的块,每个块中只包含一个进程。如果程序运行需要内存的话,操作系统就分配给它一块,如果程序运行只需要很小的空间的话,分配的这块内存很大一部分几乎被浪费了。这些在每个块中未被利用的空间,我们称之为碎片。
把主存分为大小相等且固定的一页一页的形式,页较小,相对相比于块式管理的划分力度更大,提高了内存利用率,减少了碎片。页式管理通过页表对应逻辑地址和物理地址。
页式管理虽然提高了内存利用率,但是页式管理其中的页实际并无任何实际意义。段式管理把主存分为一段段的,每一段的空间又要比一页的空间小很多 。但是,最重要的是段是有实际意义的,每个段定义了一组逻辑信息,例如,有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。段式管理通过段表对应逻辑地址和物理地址。
段页式管理机制结合了段式管理和页式管理的优点。简单来说段页式管理机制就是把主存先分成若干段,每个段又分成若干页,也就是说 段页式管理机制 中段与段之间以及段的内部的都是离散的。
快表和多级页表分别解决了页表管理怎样的问题
虚拟地址到物理地址的转换要快。
解决虚拟地址空间大,页表也会很大的问题。
- 根据虚拟地址中的页号查快表;
- 如果该页在快表中,直接从快表中读取相应的物理地址;
- 如果该页不在快表中,就访问内存中的页表,再从页表中得到物理地址,同时将页表中的该映射表项添加到快表中;
- 当快表填满后,又要登记新页时,就按照一定的淘汰策略淘汰掉快表中的一个页。
分页机制和分段机制有哪些共同点和区别
共同点:
分页机制和分段机制都是为了提高内存利用率,较少内存碎片。 页和段都是离散存储的,所以两者都是离散分配内存的方式。但是,每个页和段中的内存是连续的。区别:
页的大小是固定的,由操作系统决定;而段的大小不固定,取决于我们当前运行的程序。 分页仅仅是为了满足操作系统内存管理的需求,而段是逻辑信息的单位,在程序中可以体现为代码段,数据段,能够更好满足用户的需要。逻辑(虚拟)地址和物理地址
试说明CPU寻址。为什么需要虚拟地址空间?
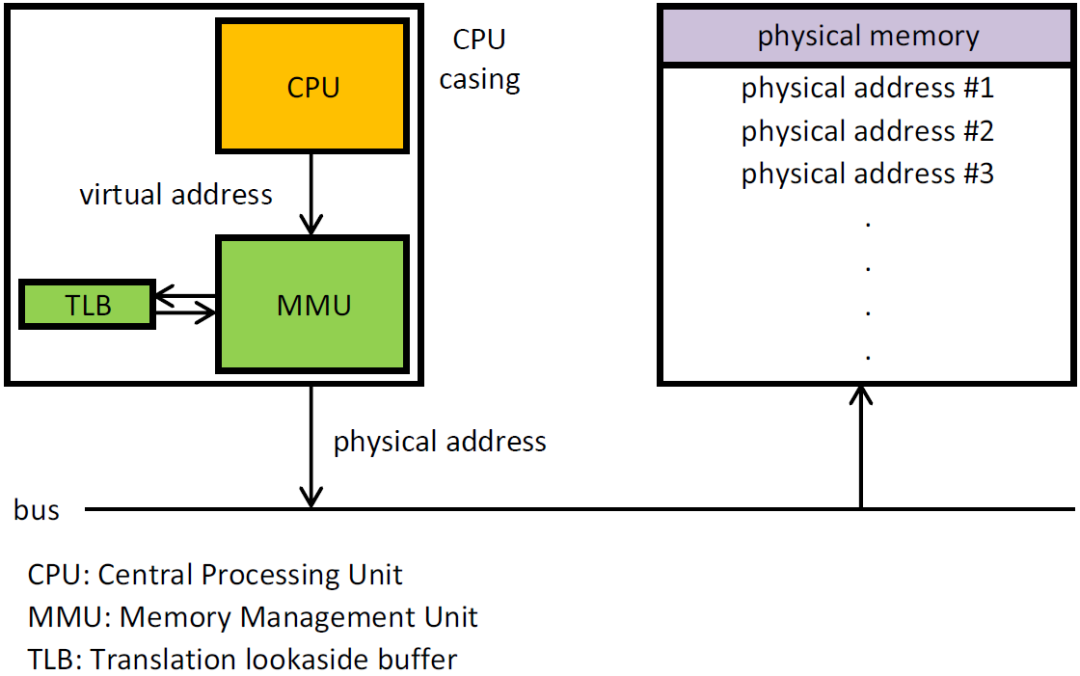
为什么要有虚拟地址空间呢?
先从没有虚拟地址空间的时候说起吧!没有虚拟地址空间的时候,程序都是直接访问和操作的都是物理内存 。但是这样有什么问题呢?
通过虚拟地址访问内存有以下优势:
虚拟内存
什么是虚拟内存(Virtual Memory)?
局部性原理
- 时间局部性 :如果程序中的某条指令一旦执行,不久以后该指令可能再次执行;如果某数据被访问过,不久以后该数据可能再次被访问。产生时间局部性的典型原因,是由于在程序中存在着大量的循环操作。
- 空间局部性 :一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址,可能集中在一定的范围之内,这是因为指令通常是顺序存放、顺序执行的,数据也一般是以向量、数组、表等形式簇聚存储的。
时间局部性是通过将近来使用的指令和数据保存到高速缓存存储器中,并使用高速缓存的层次结构实现。
空间局部性通常是使用较大的高速缓存,并将预取机制集成到高速缓存控制逻辑中实现。
虚拟内存技术实际上就是建立了 “内存一外存”的两级存储器的结构,利用局部性原理实现髙速缓存。
虚拟存储器
虚拟内存技术的实现?
- 请求分页存储管理 :建立在基本分页系统基础之上,为了支持虚拟存储器功能而增加了请求调页功能和页面置换功能。请求分页是目前最常用的一种实现虚拟存储器的方法。
- 请求分段存储管理
- 请求段页式存储管理
页面置换算法的作用?
地址映射过程中,若在页面中发现所要访问的页面不在内存中,则发生缺页中断 。
缺页中断就是要访问的页不在主存,需要操作系统将其调入主存后再进行访问。在这个时候,被内存映射的文件实际上成了一个分页交换文件。
当发生缺页中断时,如果当前内存中并没有空闲的页面,操作系统就必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。用来选择淘汰哪一页的规则叫做页面置换算法,我们可以把页面置换算法看成是淘汰页面的规则。
常见的页面置换算法有哪些?
理想情况,不可能实现,一般作为衡量其他置换算法的方法。
总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。
LRU(Least Currently Used)算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间T,当须淘汰一个页面时,选择现有页面中其T值最大的,即最近最久未使用的页面予以淘汰。
LFU(Least Frequently Used)算法会让系统维护一个按最近一次访问时间排序的页面链表,链表首节点是最近刚刚使用过的页面,链表尾节点是最久未使用的页面。访问内存时,找到相应页面,并把它移到链表之首。缺页时,置换链表尾节点的页面。也就是说内存内使用越频繁的页面,被保留的时间也相对越长。